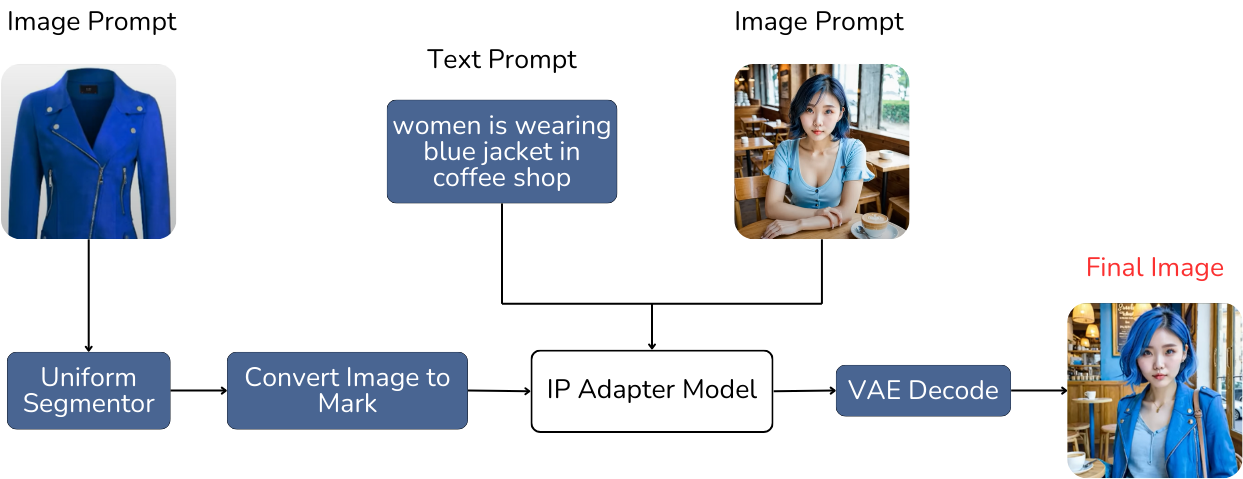
Generate Image With IPAdapter and Stable Diffusion
As previously explored, in the OOT Diffusion model, we can perform virtual try-on by providing a model image and a product image. The result is an image of the model wearing the product. This is particularly useful when we have a high-quality image of the model. This model opens up many possibilities in the fashion and e-commerce industries, enabling users to visualize products directly on a model's body easily and accurately.
In another scenario, we could develop an AI model that allows us to create a model's face entirely from scratch based on customizable features. We could then provide the model with any product and a specific environment to generate a unique image. These images could be used as promotional visuals for the product, offering flexibility and creativity in market outreach. This approach not only helps reduce costs associated with hiring, shooting, and producing images but also enables the creation of diverse and captivating promotional images tailored to each campaign.

To implement the above idea, we can consider two approaches:
-
Approach 1: Fine-tune an image generation model using a dataset of numerous images of a specific model. This way, the model can accurately learn and recreate that person's face, generating new images with a similar appearance. This technique is similar to the Laura method, allowing for the creation of realistic and consistent images based on the learned features of the original model.
-
Approach 2: Another approach is to use a tool developed by Tencent called IPAdapter (Image Processing Adapter). This tool can be leveraged to achieve similar goals with potentially different methodologies and capabilities.
Returning to the original goal of developing an AI model that can create a model's face entirely from scratch based on customizable features, the process would then allow us to provide the model with any product and a specific environment, enabling it to generate a unique image. We need to establish an image generation workflow using IPAdapter to achieve this.
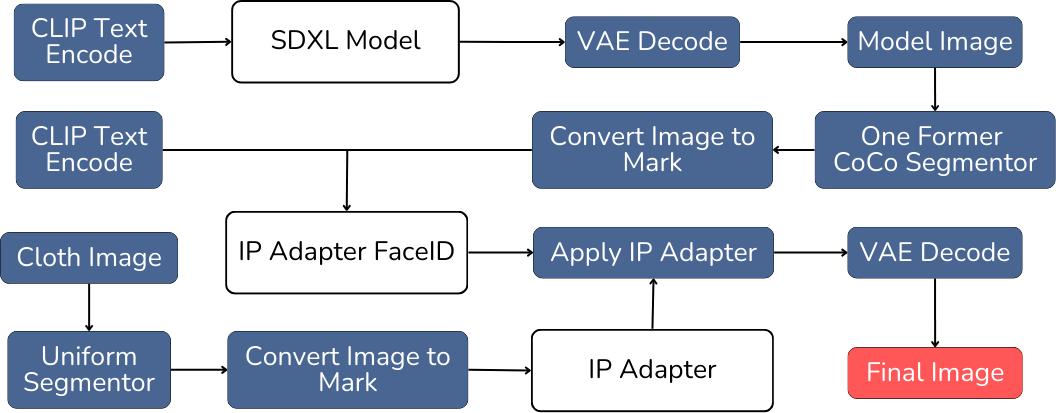
The process of generating product images using IP-Adapter and Stable Diffusion involves the following steps:
- Creating the Model’s Face Image: Use the SDXL model to generate an image of the model's face based on the provided text prompt. To ensure high-quality output, the text prompt should be detailed and focused on specific facial features. This includes aspects such as face shape, skin tone, hairstyle, eye color, expression, and other distinguishing characteristics. By providing accurate and detailed descriptions of these features in the text prompt, the SDXL model will be capable of producing a high-quality, precise image that accurately reflects the described characteristics.

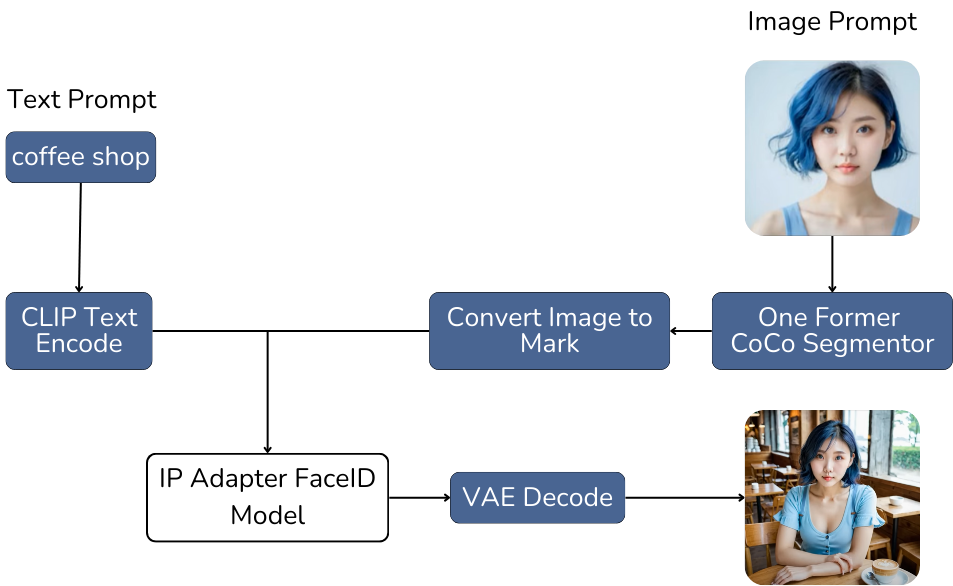
- Creating the Model’s Image with a Specific Environment: Once the model's face image is generated, pass it through the One Former Coco Segmentor model to perform image segmentation and create an overlay. Then, combine this segmented image with a text prompt describing the environment to create a more refined prompt. This combined text prompt will be used by the IP-Adapter FaceID model to generate an image of the model within the specified environment.
- Creating the Model’s Image with the Product and Environment: Finally, combine the text prompt describing the model with the environment, the model's image, and the product image. Provide this information to the IP-Adapter model to generate the final output. The result will be an image of the model wearing the product within the described environment.