IP Adapter (Image Processing Adapter)
What is IPAdapter?
Image generation has made significant strides with the success of recent text-to-image diffusion models like GLIDE, DALLE, Imagen, and Stable Diffusion. These powerful text-to-image diffusion models allow us to create images by simply writing text prompts. However, crafting a good text prompt to generate images that accurately meet specific needs is not always easy. To address this challenge, image generation models have been developed to accommodate a wider range of inputs such as text, images, and videos, thereby optimizing the output for image generation models.
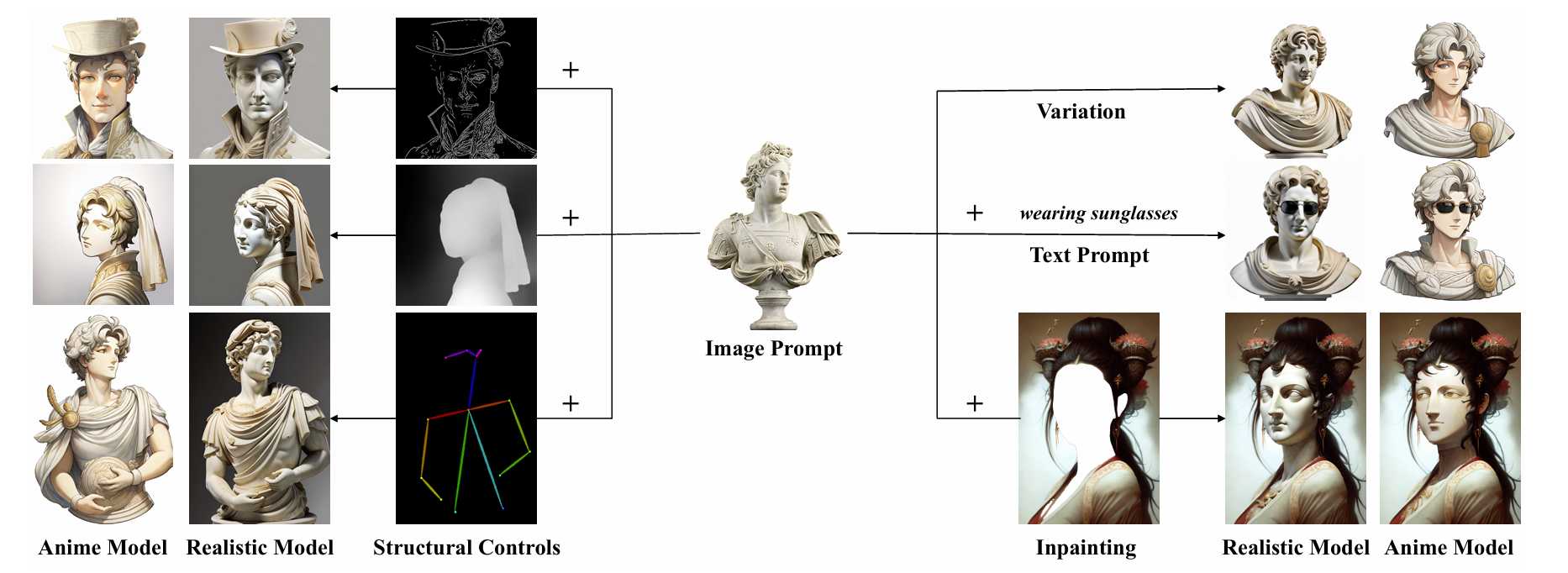
IPAdapter (Image Processing Adapter) is a new method used in image generation models, particularly in synthetic image creation systems like Stable Diffusion. This technique enhances the image generation capabilities of diffusion models by incorporating image prompts to guide the image generation process. By using image prompts, IPAdapter allows for more precise control over the generated images, improving the overall quality and relevance of the output.
To develop an AI model that can create a model's face from scratch based on customizable features, and then generate a unique image by incorporating a product and a specific environment, we can leverage the IPAdapter method. Here's a step-by-step process to build this image generation workflow using IPAdapter:
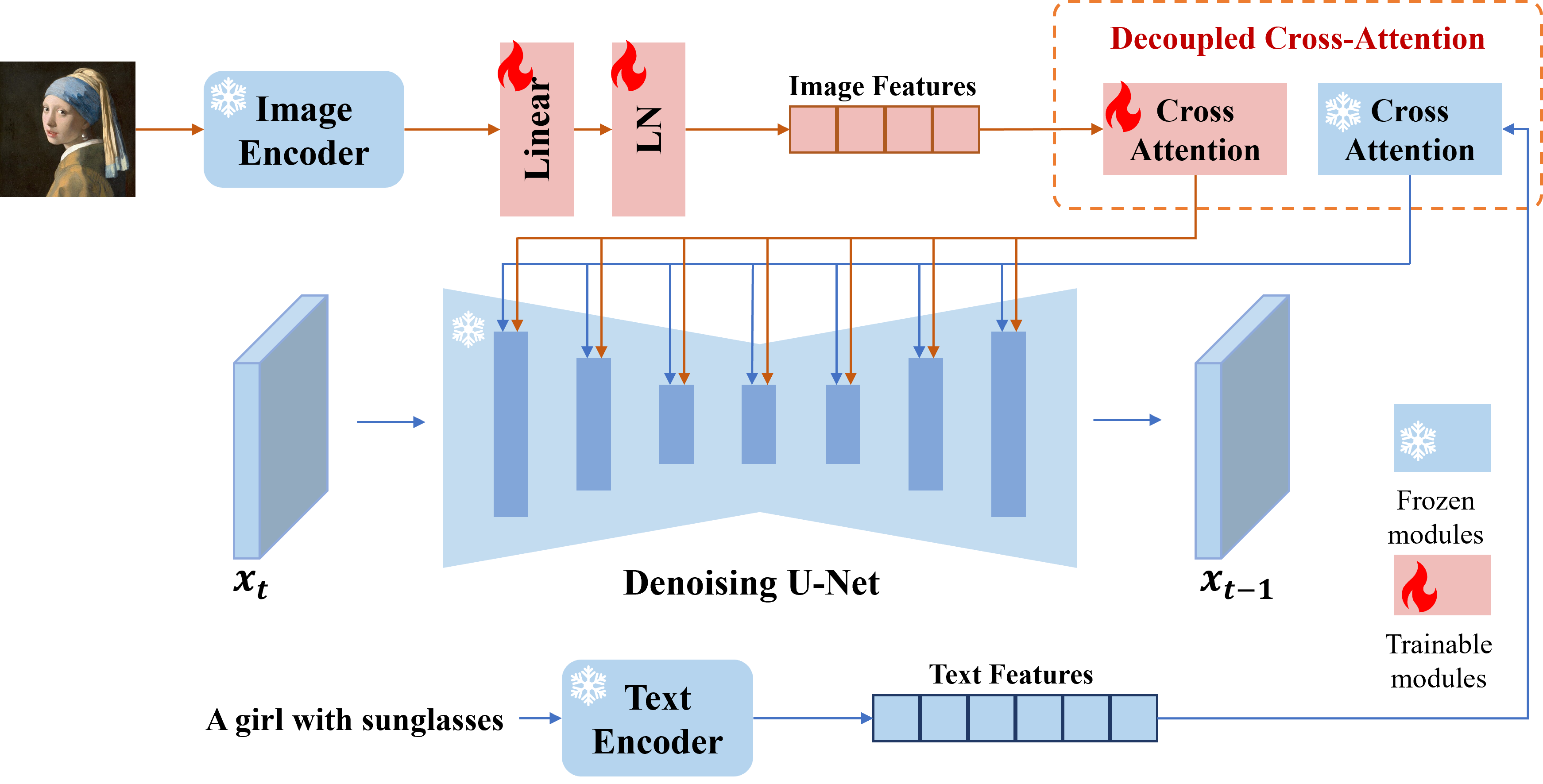
Step 1: Image Encoding
- CLIP Image Encoder: Start by using a CLIP Image Encoder to encode the input image. This encoder will extract the visual features from the image prompt, capturing key details such as facial features, pose, lighting, and other relevant aspects. These features serve as the foundational elements for guiding the image generation process.
Step 2: Text Encoding
- Text Prompt Encoding: Simultaneously, encode the text prompt (which may describe customizable facial features, the product, or the environment) using a CLIP Text Encoder. This step ensures that the textual description is converted into a form that can be integrated with the visual features.
Step 3: Decoupled Cross-Attention
- Feature Combination: Apply Decoupled Cross-Attention to combine the visual features extracted from the image prompt with the encoded features from the text prompt. This step is crucial as it merges the visual and textual information, resulting in a "final prompt" that encapsulates both the desired visual appearance and the contextual details.
Step 4: Image Generation
- Image Generation Model: Feed the final prompt into the Image Generation Model, such as Stable Diffusion. The model uses this prompt to guide the generation process, creating an image that accurately represents the customized model's face, the specified product, and the chosen environment.
Step 5: Output Refinement (Optional)
- Post-Processing: Optionally, apply additional refinement techniques or models to enhance the quality, realism, and coherence of the generated image. This could involve fine-tuning aspects such as lighting, texture, or other visual elements.
Reference: