Large Language Model & Transformer Architecture
Welcome to Nextra! This is a basic docs template. You can use it as a starting point for your own project :)
Large Language Model
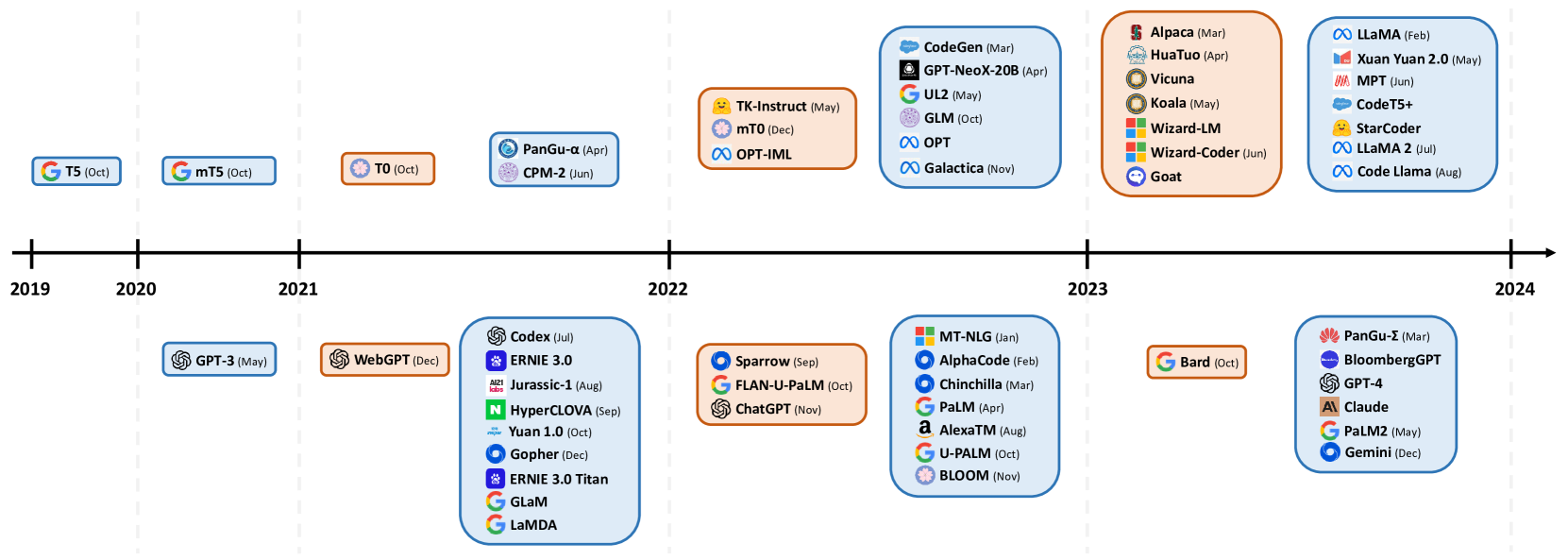
In recent years, Large Language Models (LLMs) have emerged as a revolutionary force in the field of artificial intelligence, particularly in natural language processing. These advanced AI systems are designed to understand, generate, and process natural language with remarkable proficiency.
LLMs started with simple models and have evolved through various model changes, including rule-based systems, probabilistic machine learning models, and now deep learning models. The current generation of LLMs, exemplified by models such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformer), represents a significant leap in language processing capabilities.
Transformer Architecture
Transformer is a deep learning model based on the Self-Attention mechanism to process sequence data effectively, addressing complex natural language processing problems. Transformer serves as the foundation for other renowned models, such as Bidirectional Encoder Representations from Transformer (BERT, 2019), which Google has implemented in its search engine, and in DeepMind's AlphaStar, a program capable of defeating top Starcraft players.
This model was first proposed in 2017 and replaced the Recurrent Neural Network (RNN) architecture in tasks like machine translation, which was the state-of-the-art at the time. Transformer is a deep learning model designed to solve many problems in language and speech processing, such as machine translation, language generation, classification, entity recognition, speech recognition, and text-to-speech conversion. However, unlike RNNs, Transformers do not process elements in a sequence sequentially. If the input data is a natural language sentence, the Transformer does not need to process the beginning of the sentence before the end. Due to this feature, Transformers can leverage the parallel computing power of GPUs, significantly reducing processing time.
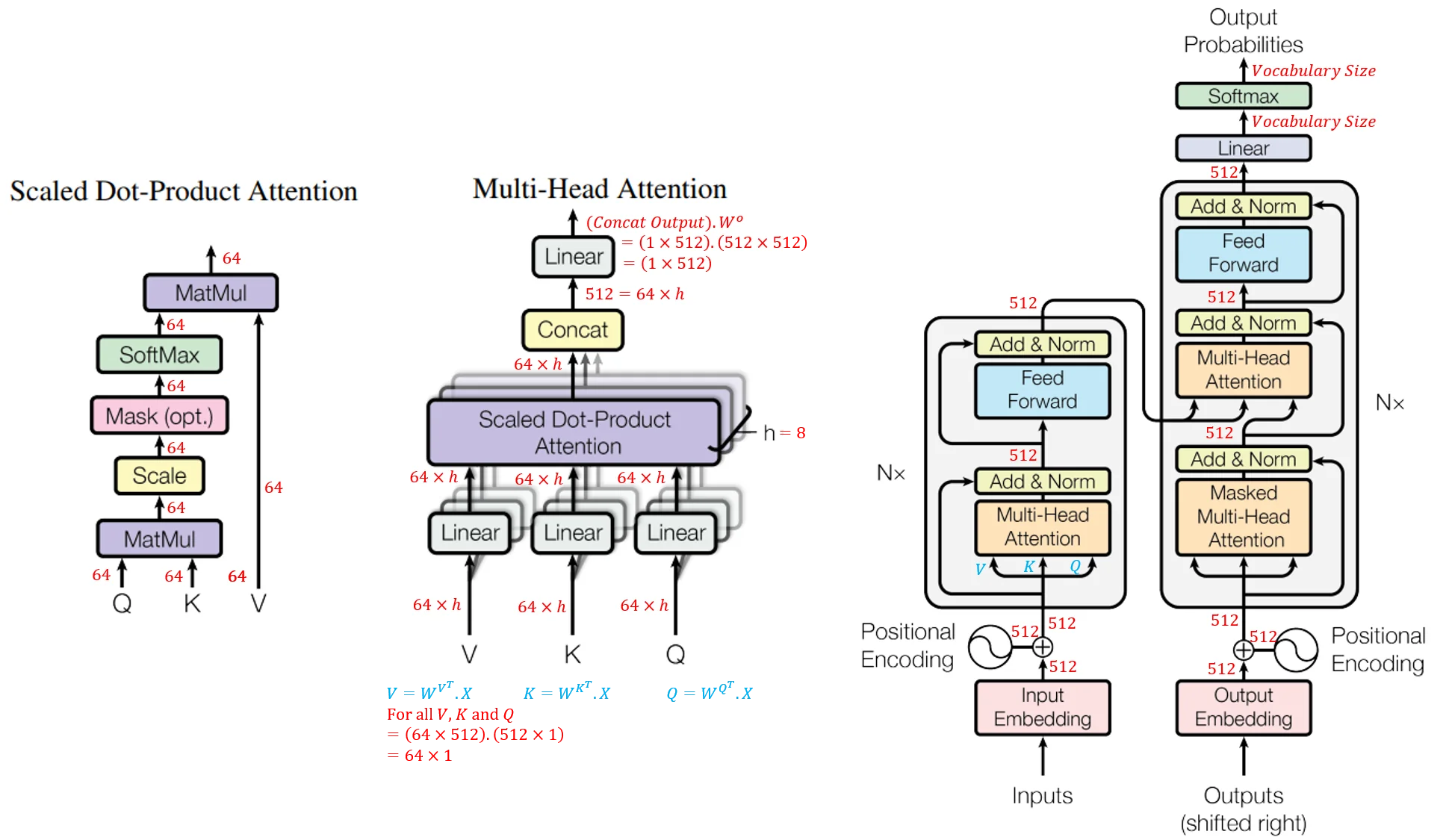
Unlike RNNs, which use recurrent architecture, Transformers utilize self-attention. In its architecture, the Transformer comprises 6 encoders and 6 decoders. Each encoder consists of two layers: Self-attention and Feedforward Neural Network (FNN).
Self-Attention is a mechanism that allows the encoder to consider other words while encoding a specific word. As a result, Transformers can understand the relationships between words in a sentence, even if they are far apart. The decoders have a similar architecture, but there is an additional attention layer between them to focus on relevant parts of the input.
Reference: