Retrieval Augmented Generation
What is RAG?
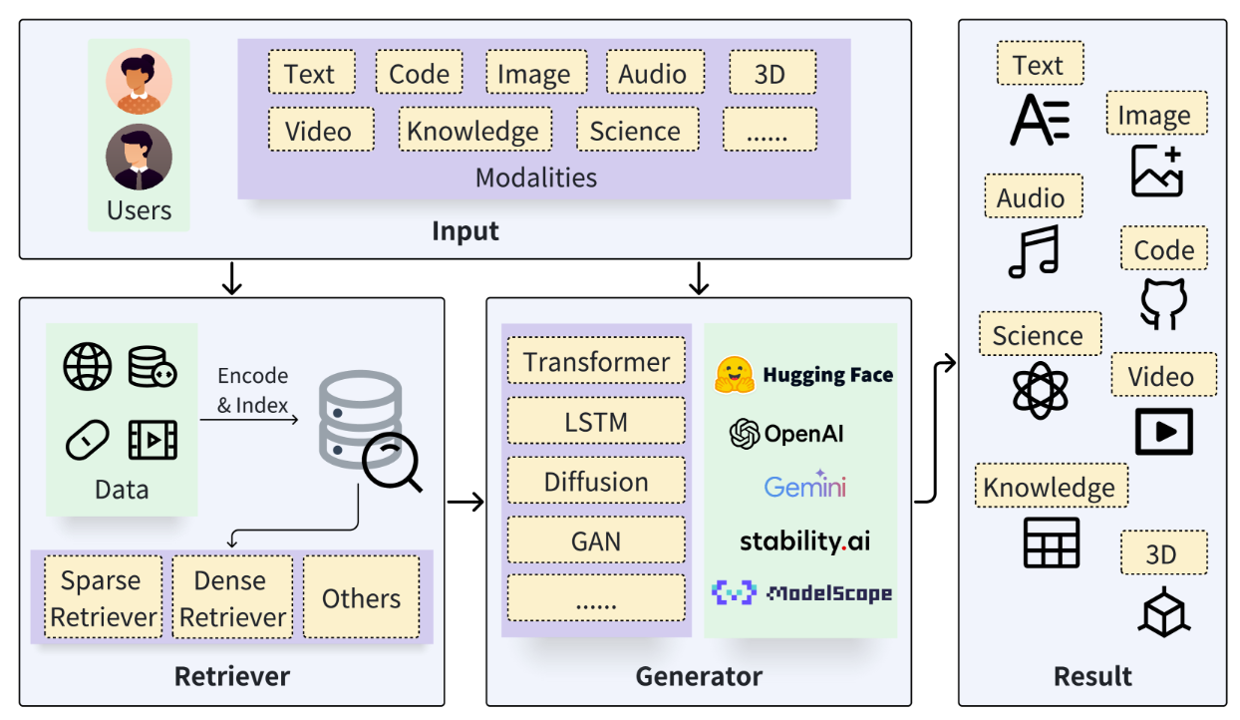
Retrieval Augmented Generation (RAG) is a process for optimizing the output of Large Language Models (LLMs). LLMs are trained on vast amounts of data and use billions of parameters to generate initial outputs for tasks such as question answering, language translation, and sentence completion. RAG enhances the already powerful capabilities of LLMs by incorporating domain-specific knowledge or an organization’s internal knowledge base, all without needing to retrain the model. This approach is a cost-effective way to improve LLM outputs, ensuring they remain relevant, accurate, and useful across various contexts.
RAG combines the strengths of both components: the ability to retrieve accurate information and the capability to generate high-quality text. This makes RAG a powerful tool for applications such as question answering, document summarization, and tasks that require a blend of information retrieval and text generation.
A Large Language Model (LLM) receives input from the user and generates responses based on the information it has been trained on. With RAG, when a request is made, an information retrieval component is employed. Its role is to enhance the search for relevant information related to the input. The retrieved data and the original input are then provided to the LLM. The LLM uses this new knowledge along with its training data to produce the most optimal response.
How it work?
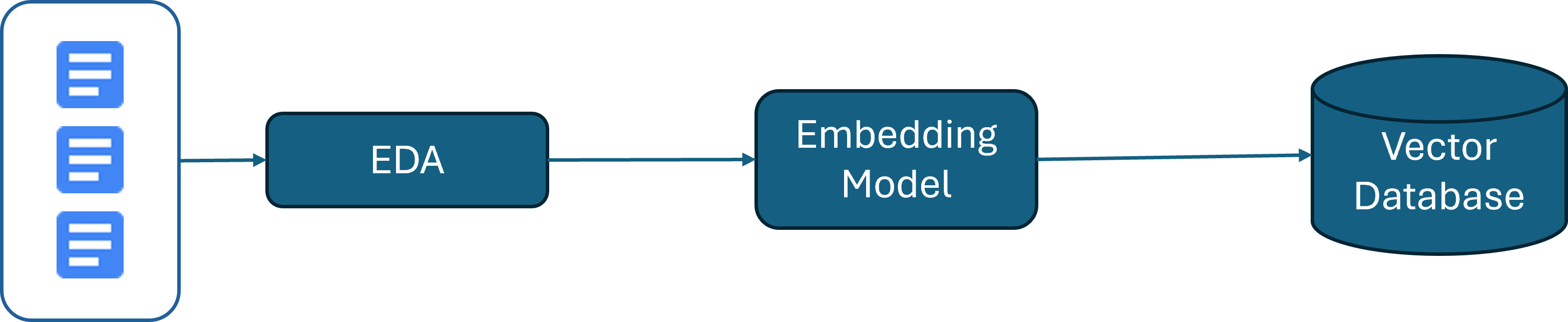
Preparing the Data:
Identify and retrieve the source documents you want to share with the LLM. The new data outside the LLM's original training dataset is referred to as external data. It can come from various data sources, such as databases or document repositories. This data may exist in different formats, including files, database records, or text.
One technique used is called an embedding model, which converts data into vectors and stores it in a vector database. This process creates an enhanced data repository, storing data in vector form to improve the performance and speed of the data retrieval process and enhance the capabilities of large language models.
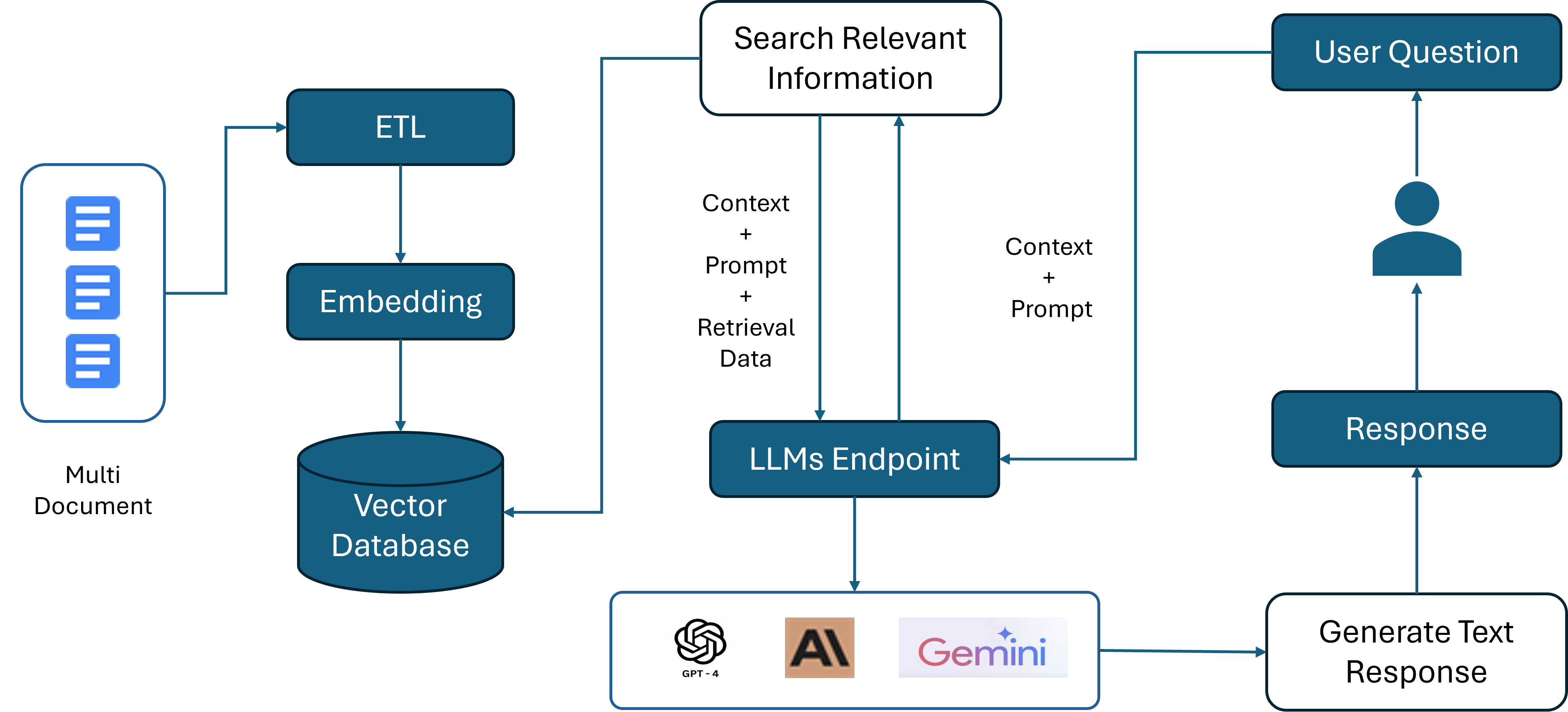
Retrieving Relevant Data:
The next step is to perform a search for relevant data. User queries are converted into vector embeddings using the same embedding model used during the enhanced data storage process. Once the data is categorized in the vector database, search algorithms will retrieve relevant information based on the user input.
Frameworks such as LangChain support various search algorithms based on data similarities, such as semantic, metadata, or original document relevance. Finally, the retrieved data is sent to the large language model for processing.
Enhancing the LLM:
After obtaining the relevant text passages, the LLM uses these passages in conjunction with the input request and context to generate a response.
Points to Consider When Applying RAG:
-
Quality of Source Documents: In machine learning model development, sourcing high-quality documents is crucial. The output quality will only be as good as the input data. Systems that produce biased results can be problematic for any organization using AI. Therefore, it is essential to ensure that source documents are free from bias to minimize discrepancies in the output.
-
Accurate and Updated Data: When collecting data for the retrieval process, ensure that the data included in the source documents is accurately cited and kept up to date.
-
Expert Review: Involve domain experts in evaluating the results before deploying the model more widely. Additionally, continue to assess the quality of the results after the model is deployed in production to ensure ongoing accuracy and relevance.
Summary:
Retrieval Augmented Generation (RAG) has revolutionized natural language processing by combining the strengths of information retrieval and text generation. This approach enhances the performance of language models by allowing them to access and incorporate relevant external information, resulting in more accurate, detailed, and coherent responses. By integrating retrieval and generation components, RAG improves tasks such as question answering and document summarization and introduces new capabilities for information extraction and language interaction. This advancement makes natural language processing systems smarter and more efficient, driving progress in research and development within the field.
Reference: