Outfiting Fusion Model
Image-based Virtual Try-On (VTON) is a popular and promising image synthesis technology in the e-commerce industry. It significantly enhances the shopping experience for consumers. As the name suggests, the goal of VTON is to generate images of a target person wearing a specific outfit.
The Outfitting over Try-on Diffusion (OOT Diffusion) model leverages the power of pre-trained latent diffusion models to create highly realistic images with natural try-on effects. It uses a specially designed UNet architecture for clothing to understand the details of the garment within the latent space.

Overview of the OOTDiffusion Model:
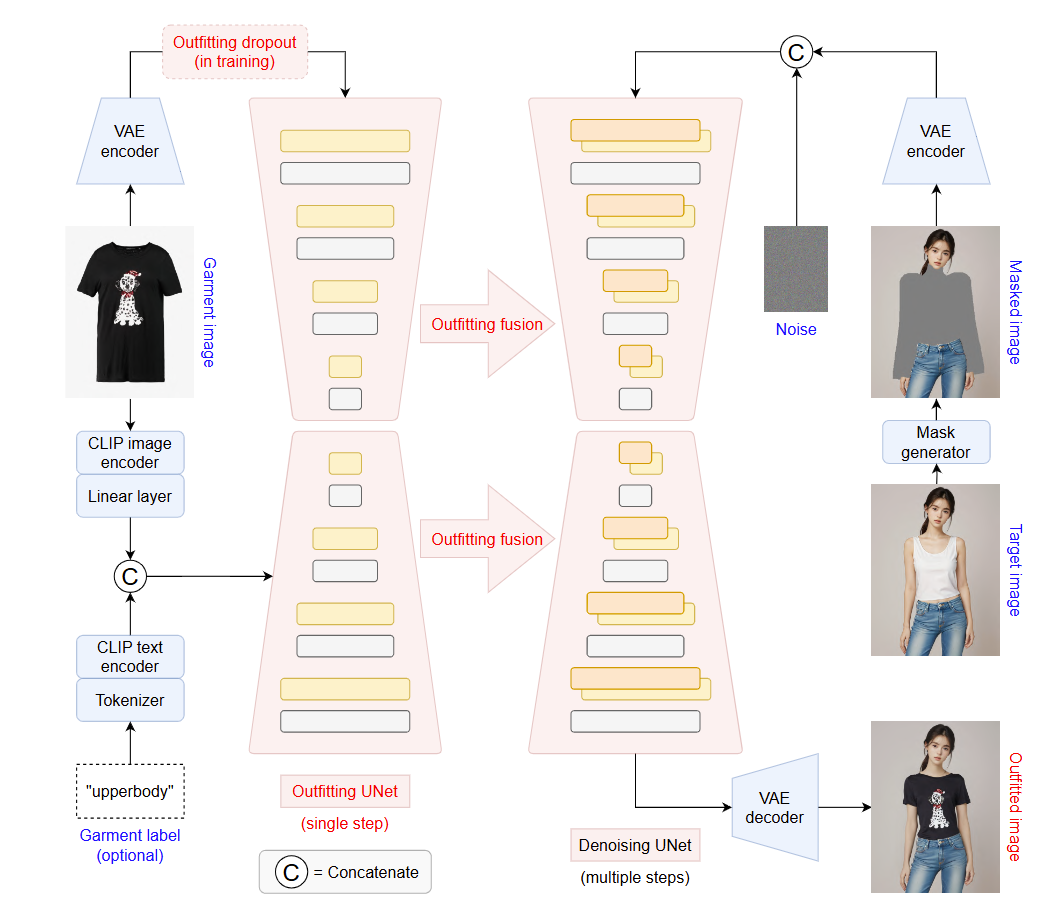
-
On the Left Side: The clothing image is encoded into latent space and processed through a UNet architecture in a single step. Along with auxiliary conditional inputs generated by CLIP encoders, the clothing features are integrated into the UNet denoising network through a clothing fusion process.
-
On the Right Side: The input is an image of a person with the target area obscured. This image is combined with Gaussian noise and fed into the UNet denoising network over multiple sampling steps. After several steps of denoising, the latent representation is decoded back into the image space as the output image through a VAE decoder.
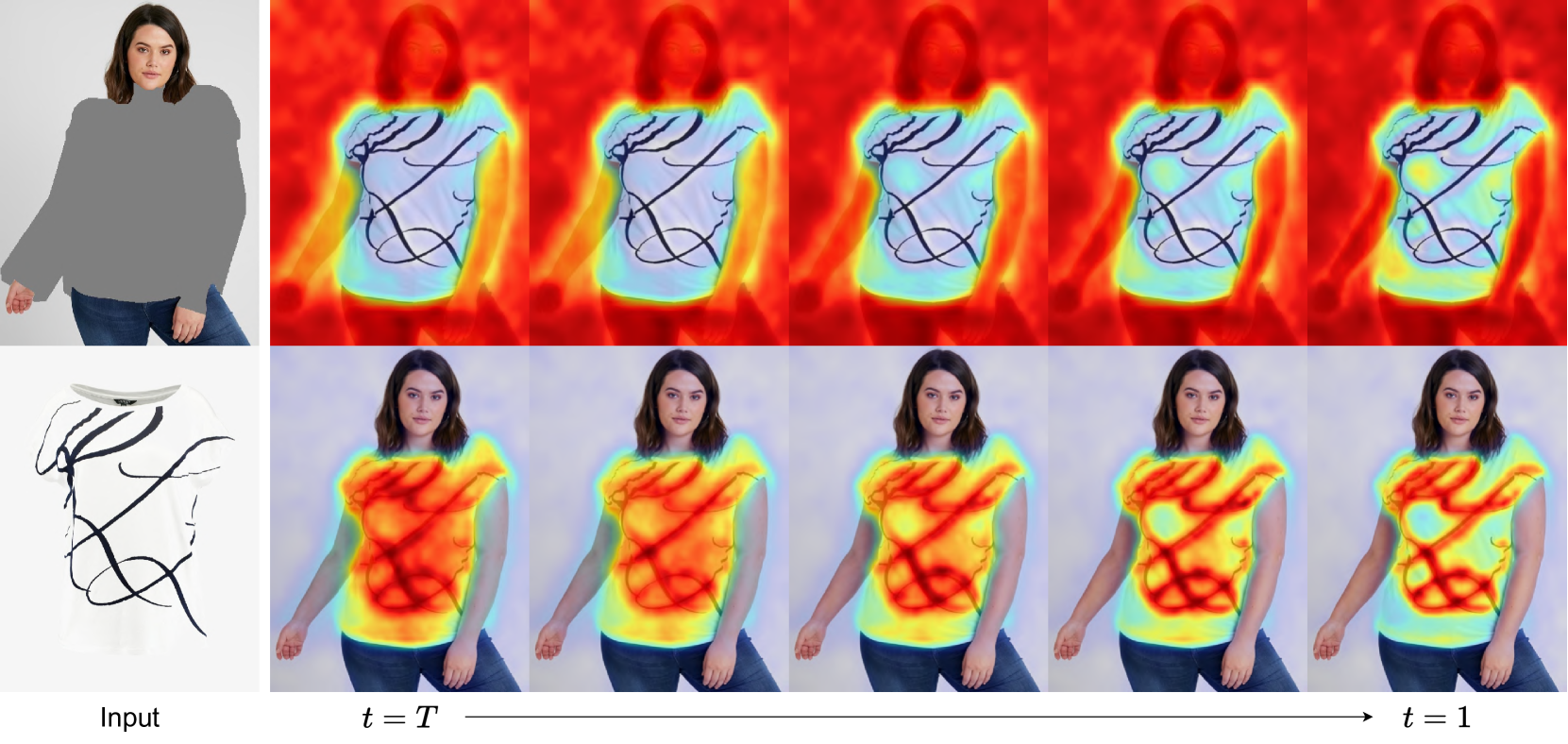
Reference: